Prompt injection is the attack where text fed to a large language model overrides its instructions — turning data the model reads into commands it obeys. It is not a fringe concern: it remains the single largest driver of agentic AI security failures in production, and OWASP maps it to six of the ten categories in its Top 10 for Agentic Applications. As agents gained the ability to call tools, read inboxes, and move money, a successful injection stopped being a party trick and became a remote-control exploit. The practical defense isn’t a smarter model — it’s a control plane that constrains every model and tool call at the boundary, which is what an AI gateway like OrcaRouter is built to provide.
Quick take: Prompt injection can’t be fully “patched” — LLMs read instructions and data as one token stream. So you defend by constraining what a manipulated model is allowed to do: filter inputs, validate outputs, enforce least privilege, and break the “lethal trifecta.” The riskier variant is indirect injection, where the payload hides in content the agent reads — no malicious user required.
What prompt injection actually is
The root cause is architectural. As OWASP puts it, LLMs “treat the system prompt, the user’s request, and any text retrieved from external sources as a single stream of tokens. There is no reliable way to mark some of those tokens as commands and others as data.” The term, coined by Simon Willison, is named after SQL injection — and shares the same flaw: trusted and untrusted content in one channel. OpenAI has called it a “frontier security challenge” with no clean solution. So prompt injection is treated as a likely permanent property of how today’s models work — you manage it, you don’t eliminate it.
Direct vs. indirect injection
There are two main shapes, and they behave very differently.
| Type | Where the payload lives | Who triggers it | 2026 prevalence |
| Direct | Typed straight into the prompt by the attacker | A malicious user | ~45% of observed attacks |
| Indirect / stored | Hidden in data the agent reads (email, web page, RAG doc, tool output) | An innocent user — or no one | 55%+ of attacks, growing fast |
Direct injection is the classic jailbreak: “ignore your previous instructions and…” typed by someone with access. Indirect (or stored) injection is the dangerous one. The malicious instruction is planted in content the agent will later process — a calendar invite, a support ticket, a scraped web page, a document in a retrieval store. A trusting user simply asks the agent to “summarize this,” and the hidden command runs in their privileged context. Indirect attacks reportedly carry 20–30% higher success rates because they arrive through trusted sources.
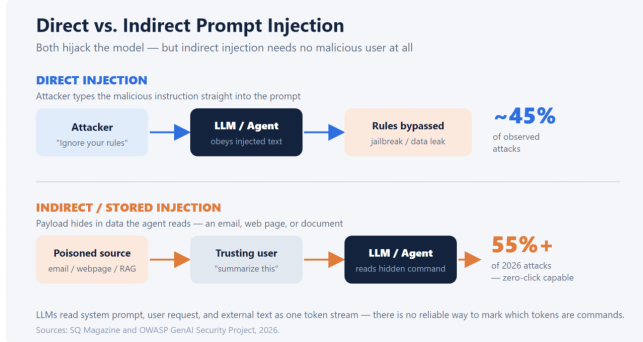
Indirect injection needs no malicious user — and is now the majority of observed attacks. Source: SQ Magazine.
Real 2026 exploits and statistics
This is no longer theoretical:
- EchoLeak (CVE-2025-32711): the first real-world zero-click prompt injection in a production LLM system. A single crafted email — never opened by the victim — let an attacker exfiltrate Microsoft 365 Copilot data (chats, OneDrive, SharePoint, Teams). It carried a CVSS score of 9.3 and chained past Microsoft’s cross-prompt-injection classifier.
- In the wild at scale: in March 2026, Palo Alto’s Unit 42 documented the first large-scale indirect injection attacks in production, including ad-review evasion and system-prompt leakage on live commercial platforms.
- It bypasses access controls: indirect injection extracted hidden system prompts in 38% of tested systems and bypassed role-based access controls in 42% of examined workflows.
- It’s most of the breach picture: over 30% of AI-related breaches reported through 2026 involved some form of prompt manipulation.
Why it’s the #1 agentic failure
A chatbot that only emits text can leak data; an agent can act on the injected instruction. Willison’s lethal trifecta explains why agents are uniquely exposed: any system combining (1) access to private data, (2) exposure to untrusted content, and (3) the ability to communicate externally can be turned into an exfiltration tool by one injected prompt. Most useful agents have all three. OWASP’s advisory data reflects the blast radius — the repositories with the most security advisories are agentic frameworks and coding agents like n8n, Claude Code, and AutoGPT.
How to defend against prompt injection
You can’t make the model immune, so you constrain the manipulated model’s options. Layer these — ideally at a single enforcement point in front of every call:
- Treat all input as untrusted. Scan user input, tool outputs, and retrieved documents for injection patterns before the model sees them.
- Validate every output. Never auto-execute model output. Check tool calls and arguments against an allow-list, and block outbound links or images that could exfiltrate data.
- Enforce least privilege. Give each agent the minimum tools and scopes for its task; gate payments, deletes, and external sends behind explicit approval.
- Break the lethal trifecta. Don’t let one agent hold private data, untrusted content, and an external channel at once — remove a leg structurally rather than relying on detection.
- Enforce it at a gateway. A model-agnostic control plane gives you input filtering, output validation, PII redaction, guardrails with risk scoring, and full logging once — across every provider.

No single control is enough — layer them, and enforce them at the boundary.
This is precisely what a security-focused AI gateway provides: one place to filter inputs, redact PII, score and block anomalous requests, and log every call — so injection defenses don’t have to be re-implemented per agent or per model.
The bottom line
Prompt injection is OWASP’s #1 LLM risk in 2026 because it exploits how models fundamentally work, and because agents turned it from a content problem into an action problem. EchoLeak proved zero-click exfiltration is real; the in-the-wild numbers prove it’s common. You won’t patch your way out — but you can shrink the blast radius: assume the model is steerable, validate what it tries to do, strip its excess privileges, and enforce all of it at a gateway you control.
Frequently asked questions
What is prompt injection? An attack where text supplied to an LLM overrides its instructions, causing it to follow attacker commands. Because models read instructions and data as one token stream, they can’t reliably tell the two apart.
What’s the difference between direct and indirect prompt injection? Direct injection is typed into the prompt by an attacker. Indirect (stored) injection hides the payload in content the agent later reads — an email, web page, or document — so an innocent user triggers it.
Can prompt injection be prevented completely? No. OpenAI calls it a frontier security challenge with no clean solution. You mitigate it with layered defenses, not a single fix.
What was the EchoLeak attack? EchoLeak (CVE-2025-32711) was the first real-world zero-click prompt injection in production: a single email could silently exfiltrate Microsoft 365 Copilot data, CVSS 9.3.
What is the lethal trifecta? Simon Willison’s term for the risky mix of private-data access, untrusted content, and an external channel — any agent with all three can be turned into an exfiltration tool.